Ruby is a dynamic, interpreted, open-source programming language known for its simplicity, productivity, and its “human-readable” syntax. Ruby is often used in web development, particularly with the Ruby on Rails framework. It supports object-oriented, functional, and imperative programming paradigms.
The most known and used Ruby Virtual Machine is the Matz Ruby Interpreter (aka CRuby), developed by Yukihiro Matsumoto (aka Matz), the creator of Ruby. All other Ruby implementation such as JRuby, TruffleRuby and so on are out of the scope of this blog post.
The MRI implements the Global Interpreter Lock, a mechanism to ensure that one and only one thread runs at the same time effectively limiting true parallelism. Reading between the lines, one can understand that Ruby is multi-threaded, but with a parallelism limit of 1 (or maybe more 👀).
Many popular Gems such as Puma, Sidekiq, Rails, Sentry are multi-threaded
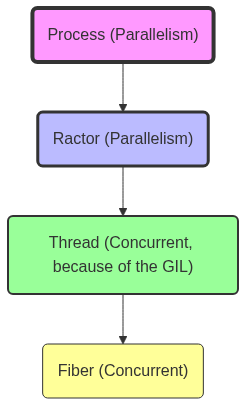
Process 💎, Ractor 🦖, Threads 🧵 and Fibers 🌽
Here’s an overview of all the intricated layers in Ruby that deal with concurrency and parallelism (and yes they are not the same thing). Let’s explore each of them in depth.
You’re inside a simulation of a simulation…inside another giant simulation! laughs harder
By default, all this nested structure exist in the most simple Ruby program you can think of.
I need you to trust me, so here is a proof :
#!/usr/bin/env ruby
# Print the current Process ID
puts "Current Process ID: #{Process.pid}"
# Ractor
puts "Current Ractor: #{Ractor.current}"
# Print the current Thread
puts "Current Thread: #{Thread.current}"
# Print the current Fiber
puts "Current Fiber: #{Fiber.current}"
Current Process ID: 6608
Current Ractor: #<Ractor:#1 running>
Current Thread: #<Thread:0x00000001010db270 run>
Current Fiber: #<Fiber:0x00000001012f3ee0 (resumed)>
Every piece of Ruby code runs in a Fiber, that runs in a Thread, that runs in a Ractor, that runs in a Process
Process 💎
This one is probably the easier to understand. Your computer is running many processes in parallel for example : your window manager and the web browser you are using right now are two processes that runs in parallel.
So to run Ruby processes in parallel, you can just open two terminal windows and run one program in each and voilà (or you can also run fork in your program).
In this case, scheduling is orchestrated by the Operating System, memory is isolated between process A and process B (like, you don’t want Word to have access to your browser memory ?)
If you want to pass data from process A to process B, you need interprocessus communication mechanisms such as pipes, queues, sockets, signals or more trivial stuff like a shared file where one read and the other write (beware of race-condition then!)
Ractor 🦖
Ractors are a new, experimental feature designed to achieve parallel execution within a Ruby program. Managed by the VM (and not the Operating System), Ractors use native threads under the hood to run in paralllel. Each Ractor behaves like an independent virtual machine (VM) inside the same Ruby process, with its own isolated memory. “Ractor” stands for “Ruby Actors,” and, as in the Actor model, Ractors communicate by passing messages to exchange data without the need for shared memory, avoiding the Mutex approach. Each Ractor has its own GIL, allowing them to run independently without interference from other Ractors.
In summary, Ractors offer a model for true parallelism where memory isolation prevents race conditions, and message-passing provides a structured and safe way for Ractors to interact, enabling efficient parallel execution in Ruby.
Lets try it !1
require 'time'
# `sleep` used here is not really CPU bound but it’s used to simplify the example
def cpu_bound_task()
sleep(2)
end
# Divide a large range into smaller chunks
ranges = [
(1..25_000),
(25_001..50_000),
(50_001..75_000),
(75_001..100_000)
]
# Start timing
start_time = Time.now
# Create Ractors to calculate the sum in parallel with delays
ractors = ranges.map do |range|
Ractor.new(range) do |r|
cpu_bound_task()
r.sum
end
end
# Collect results from all Ractors
sum = ractors.sum(&:take)
# End timing
end_time = Time.now
# Calculate and display total execution time
execution_time = end_time - start_time
puts "Total sum: #{sum}"
puts "Parallel Execution time: #{execution_time} seconds"
# Start timing
start_time = Time.now
sum = ranges.sum do |range|
cpu_bound_task()
range.sum
end
# End timing
end_time = Time.now
# Calculate and display total execution time
execution_time = end_time - start_time
puts "Total sum: #{sum}"
puts "Sequential Execution time: #{execution_time} seconds"
warning: Ractor is experimental, and the behavior may change in future versions of Ruby! Also there are many implementation issues.
Total sum: 5000050000
Parallel Execution time: 2.005622 seconds
Total sum: 5000050000
Sequential Execution time: 8.016461 seconds
And here is the proof that Ractors run in parallel.
As I said earlier they are fairly experimental and not used in many Gems nor code you might see.
The are really here to distribute intensive CPU bound tasks to all you CPU cores.
Thread 🧵
The key difference between OS threads and Ruby threads lies in how they handle concurrency and resource management. OS threads are managed by the operating system, allowing them to run in parallel across multiple CPU cores, making them more resource-intensive but enabling true parallelism. In contrast, Ruby threads—especially in MRI Ruby—are managed by the interpreter and restricted by the Global Interpreter Lock (GIL), meaning only one thread can execute Ruby code at a time, limiting them to concurrency without true parallelism. This makes Ruby threads lightweight (also known as “Green Threads”) but unable to fully utilize multicore systems (as opposed to Ractor that allow multiple “Ruby VM” to run in the same process).
Let’s take a look at this code snippet that uses threads :
require 'time'
def slow(name, duration)
puts "#{name} start - #{Time.now.strftime('%H:%M:%S')}"
sleep(duration)
puts "#{name} end - #{Time.now.strftime('%H:%M:%S')}"
end
puts 'no threads'
start_time = Time.now
slow('1', 3)
slow('2', 3)
puts "total : #{Time.now - start_time}s\n\n"
puts 'threads'
start_time = Time.now
thread1 = Thread.new { slow('1', 3) }
thread2 = Thread.new { slow('2', 3) }
thread1.join
thread2.join
puts "total : #{Time.now - start_time}s\n\n"
no threads
1 start - 08:23:20
1 end - 08:23:23
2 start - 08:23:23
2 end - 08:23:26
total : 6.006063s
threads
1 start - 08:23:26
2 start - 08:23:26
1 end - 08:23:29
2 end - 08:23:29
total : 3.006418s
The Ruby interpreter controls when threads are switched, typically after a set number of instructions or when a thread performs a blocking operation like file I/O or network access. This allows Ruby to be effective for I/O-bound tasks, even though CPU-bound tasks remain limited by the GIL.
There is some shenanigans available for you to use, like the priority attribute instruct the interpreter that you want it to favor the run of a thread with a higher priority, without any guarantee the the Ruby VM will honor it. If you want to go more brutal Thread.pass is available. As a rule of thumb, it’s considered a bad idea to play with those low level instructions in your code.
But why the need for the GIL in the first place ? Because the internal structures of the MRI are not thread safe! It’s very specific to the MRI other Ruby implementations like JRuby don’t have those limitations.
Finally, do not forget that threads share memory, so this open the door to race conditions. Here is an overcomplicated example for you to understand this. It relies on the fact that class level variables shares the same memory space. Using class variables for something else than a constant is considered a bad practice.
# frozen_string_literal: true
class Counter
# Shared class variable
@@count = 0
def self.increment
1000.times do
current_value = @@count
sleep(0.0001) # Small delay to allow context switches
@@count = current_value + 1 # Increment the count
end
end
def self.count
@@count
end
end
# Create an array to hold the threads
threads = []
# Create 10 threads that all increment the @@count variable
10.times do
threads << Thread.new do
Counter.increment
end
end
# Wait for all threads to finish
threads.each(&:join)
# Display the final value of @@count
puts "Final count: #{Counter.count}"
# Check if the final count matches the expected value
if Counter.count == 10_000
puts "Final count is correct: #{Counter.count}"
else
puts "Race condition detected: expected 10000, got #{Counter.count}"
end
Final count: 1000
Race condition detected: expected 10000, got 1000
The sleep here force a context switch to another thread as it’s an I/O operation. This results in the @@count value being reset to previous value when the context changes back from thread to thread.
In your day to day code, you should not use thread, but it’s good to know that they exists under the hood in most of the Gems we use daily!
Fiber 🌽
Here we go for the final nested level ! Fiber is a very lightweight cooperative concurrency mechanism. Unlike threads, fibers are not preemptively scheduled; instead, they explicitly pass control back and forth. Fiber.new take the block you will execute in you fiber. From there, you can use Fiber.yield and Fiber.resume to control the back and forth between the fibers. As we saw earlier, Fibers run inside the same Ruby thread (so they share the same memory space). As every other concept highlighted in this blog post, you should consider Fiber as a very low level interface and I would avoid building a lot of code based on them. The only valid use case for me is Generator. With Fiber s it’s relatively easy to create a lazy generator as in the code below.
def fibernnacci
Fiber.new do
a, b = 0, 1
loop do
Fiber.yield a
a, b = b, a + b
end
end
end
fib = fibernnacci
5.times do
puts Time.now.to_s
puts fib.resume
end
2024-10-19 15:58:54 +0200
0
2024-10-19 15:58:54 +0200
1
2024-10-19 15:58:54 +0200
1
2024-10-19 15:58:54 +0200
2
2024-10-19 15:58:54 +0200
3
As you can see in this output, code lazy generates values only when they need to be consumed. This allows for interesting patterns and properties you might need in your toolbelt.
Once again, as it’s low level API, using Fibers in your code is probably not the best idea. The most known Gem that heavily use Fibers is the Async Gem (used by Falcon).
Wrap Up
Ruby provides several concurrency models, each with unique characteristics suited for different tasks.
- Processes offer full memory isolation and can run in parallel across CPU cores, making them great for tasks that need complete separation but are resource-heavy.
- Ractors, introduced in Ruby 3, also provide parallelism with memory isolation, but within the same process, allowing for safer parallel execution by passing messages between ractors.
- Threads are lighter than processes, sharing memory within the same process, and can run concurrently, but they require careful synchronization to avoid race conditions.
- Fibers are the lightest concurrency mechanism, offering cooperative multitasking by manually yielding control. They share the same memory and are most useful for building generators or coroutines, rather than parallel execution.
With that knowledge, you now have arguments to enter the never-ending Puma (threads-first approach) vs. Unicorn (process-first approach) debate. Just remember, discussing this topic is like trying to explain the difference between Vi and Emacs! It’s an exercise left to the reader to find out which one is the winner!2
-
spoiler: it depends ↩︎